Duality between confidence sets and hypothesis tests
Contents
Duality between confidence sets and hypothesis tests¶
We will observe \(X \sim \mathbb P_\mu\), where \(\mu \in \Theta\).¶
\(\Theta\) is known
\(\theta \rightarrow \mathbb P_\theta\) is known
\(\mu\) is unknown
\(X\) takes values in \(\mathcal X\).
(We will ignore issues of measurability here: tacitly assume that for all \(\theta \in \Theta\), \(A_\eta\) is \(\mathbb P_\theta\)-measurable and that \(\mathcal I(X)\) is set-valued \(\mathbb P_\theta\)-measurable function.)
Definition
\(A_\theta \subset \mathcal X\) is the acceptance region for a level-\(\alpha\) test of the hypothesis \(\mu = \theta\) iff
Definition
\(\mathcal I(X)\) is a \(1-\alpha\) confidence set for \(\mu\) iff
Proposition
Suppose
is a family of level-\(\alpha\) acceptance regions. Then
is a \(1-\alpha\) confidence set for \(\mu\).
Proof
For any \(\theta \in \Theta\),
We will use this approach—inverting tests—to construct confidence sets.¶
We are interested in confidence bounds for real-valued parameters, typically 1-sided bounds
Typically, one-sided tests for a one-dimensional location parameter lead to one-sided confidence bounds for the parameter
Inverting a family of tests that rejects \(\mu = \theta\) when \(X\) is sufficiently small typically leads to an upper confidence bound for \(\mu\)
Inverting a family of tests that rejects \(\mu = \theta\) when \(X\) is sufficiently large typically leads to a lower confidence bound for \(\mu\)
Inverting a family of tests that rejects \(\mu = \theta\) when \(X\) is sufficiently “extreme” typically leads to a confidence interval for \(\mu\)
(Exceptions arise from non-monotone likelihood ratios, etc.)
Example: one-sided binomial tests¶
Consider \(n\) independent, uniform draws (i.e., a random sample with replacement) from a \(\{0, 1\}\) population containing a fraction \(p\) of 1s. Let \(X\) denote the number of 1s in the random sample. Then \(X\) has a Binomial distribution with parameters \(n\) and \(p\).
In particular,
for \(0 \le k \le n\).
To find a one-sided lower confidence bound for \(p\) in a Binomial\((n,p)\) distribution, with \(n\) known, we would invert one-sided upper tests, that is, tests that reject the hypothesis \(p = \pi\) when \(X\) is large.
The form of the acceptance region for the test is:
where
Let’s see this graphically:
# This is the first cell with code: set up the Python environment
%matplotlib inline
import matplotlib.pyplot as plt
import math
import numpy as np
import scipy as sp
import scipy.stats
from scipy.stats import binom
import pandas as pd
from ipywidgets import interact, interactive, fixed
import ipywidgets as widgets
from IPython.display import clear_output, display, HTML
def binomialHiLite(n, p, alpha):
'''
Plots probability histogram for a binomial with parameters n and p,
highlighting the upper alpha quantile in yelow.
The blue region corresponds to the acceptance region for a level-alpha
test about p.
Plots a red vertical line at the expected value.
'''
fig, ax = plt.subplots(nrows=1, ncols=1)
x = np.arange(n+1)
val = binom.ppf(1-alpha, n, p)
inx = np.searchsorted(x, val, side="right")
xb = x[:inx]
xy = x[inx:]
width = 1.0
ax.bar(xb, binom.pmf(xb, n, p), width, color='b', align='center')
hilit = ax.bar(xy, binom.pmf(xy, n, p), width, color='y', align='center')
plt.xlim([-width,n+width])
plt.axvline(x=n*p, color='r')
probStr = str(round(100*(1-binom.cdf(x[inx-1],n, p)),2))
label = r'$\mathbf{P}(X \geq ' + str(x[inx]) + r') \approx' + probStr + '$'
plt.legend([hilit[0]], [label], loc = 'best')
interact(binomialHiLite, n=widgets.IntSlider(min=5, max=300, step=1, value=30),\
p=widgets.FloatSlider(min=0.001, max=1, step=0.001, value=.5),\
alpha=widgets.FloatSlider(min=0.0, max=1.0, step=0.001, value=.05)\
)
<function __main__.binomialHiLite>
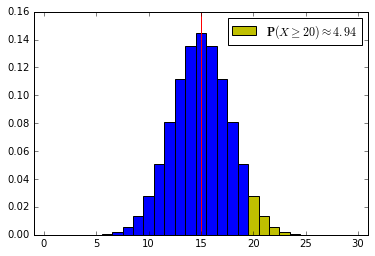
Inverting the test to find a confidence bound¶
To turn this family of tests into a lower confidence bound, we need to find
that is,
The following code implements this, using a bisection search.
def bisect(lo, hi, tol, fun):
mid = (lo+hi)/2.0
while (hi-lo)/2 > tol:
if fun(mid) == 0.0:
return mid
elif fun(lo)*fun(mid) < 0.0:
hi = mid
else:
lo = mid
mid = (lo+hi)/2.0
return mid
def binoLowerCL(n, x, cl = 0.975, inc=0.000001, p = None):
"Lower confidence level cl confidence interval for Binomial p, for x successes in n trials"
if p is None:
p = float(x)/float(n)
lo = 0.0
if (x > 0):
f = lambda q: cl - scipy.stats.binom.cdf(x-1, n, q)
lo = bisect(0.0, p, inc, f)
return lo
Let’s use the code to find a lower confidence bound for \(p\) if 50 iid draws from a {0, 1} population yield 40 1s and 10 0s.
p_lower_bound = binoLowerCL(50, 40, cl=0.95)
print p_lower_bound
0.68440322876
Now let’s check that against the probability histogram. Note that reducing \(p\) below \(0.6844\) drops the upper tail probability below 5%; for \(p > 0.6844\) the probability is at least 5%, so the confidence interval is \([0.6844, 1]\):
interact(binomialHiLite, n=widgets.IntSlider(min=5, max=300, step=1, value=50),\
p=widgets.FloatSlider(min=0.001, max=1, step=0.001, value=p_lower_bound),\
alpha=widgets.FloatSlider(min=0.0, max=1.0, step=0.001, value=.05)\
)
<function __main__.binomialHiLite>
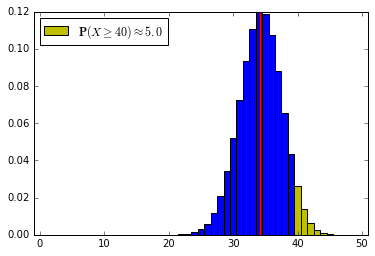
Upper confidence bounds for \(p\)¶
For completeness, here’s the code to find an upper confidence bound for Binomial \(p\):
def binoUpperCL(n, x, cl = 0.975, inc=0.000001, p = None):
"Upper confidence level cl confidence interval for Binomial p, for x successes in n trials"
if p is None:
p = float(x)/float(n)
hi = 1.0
if (x < n):
f = lambda q: scipy.stats.binom.cdf(x, n, q) - (1-cl)
hi = bisect(p, 1.0, inc, f)
return hi
What’s next?¶
We will consider some methods for constructing confidence bounds that work where the normal approximation failed, focusing at first on (lower) one-sided confidence intervals for the mean of bounded populations